


可以使用自编码器进行降维,也可以通过加入噪声学习来实现降噪。
以下使用单个隐藏层来训练 mnist 数据集并共享对称权重参数。
模型本身并不难,调试过程中有几点需要注意:
1、建立模型
import numpy as np import tensorflow as tf class AutoEncoder(object): ''' 使用对称结构,解码器重用编码器的权重参数 ''' def __init__(self, input_shape, h1_size, lr): tf.reset_default_graph()# 重置默认计算图,有时出错后内存还一团糟 with tf.variable_scope('auto_encoder', reuse=tf.AUTO_REUSE): self.W1 = self.weights(shape=(input_shape, h1_size), name='h1') self.b1 = self.bias(h1_size) self.W2 = tf.transpose(tf.get_variable('h1')) # 共享参数,使用其转置 self.b2 = self.bias(input_shape) self.lr = lr self.input = tf.placeholder(shape=(None, input_shape), dtype=tf.float32) self.h1_out = tf.nn.softplus(tf.matmul(self.input, self.W1) + self.b1)# softplus,类relu self.out = tf.matmul(self.h1_out, self.W2) + self.b2 self.optimizer = tf.train.AdamOptimizer(learning_rate=self.lr) self.loss = 0.1 * tf.reduce_sum( tf.pow(tf.subtract(self.input, self.out), 2)) self.train_op = self.optimizer.minimize(self.loss) self.sess = tf.Session() self.sess.run(tf.global_variables_initializer()) def fit(self, X, epoches=100, batch_size=128, epoches_to_display=10): batchs_per_epoch = X.shape[0] // batch_size for i in range(epoches): epoch_loss = [] for j in range(batchs_per_epoch): X_train = X[j * batch_size:(j + 1) * batch_size]loss, _ = self.sess.run([self.loss, self.train_op], feed_dict={self.input: X_train}) epoch_loss.append(loss) if i % epoches_to_display == 0: print('avg_loss at epoch %d :%f' % (i, np.mean(epoch_loss))) # return self.sess.run(W1) # 权重初始化参考别人的,这个居然很重要!用自己设定的截断正态分布随机没有效果 def weights(self, shape, name, constant=1): fan_in = shape[0] fan_out = shape[1] low = -constant * np.sqrt(6.0 / (fan_in + fan_out)) high = constant * np.sqrt(6.0 / (fan_in + fan_out)) init = tf.random_uniform_initializer(minval=low, maxval=high) return tf.get_variable(name=name, shape=shape, initializer=init, dtype=tf.float32) def bias(self, size): return tf.Variable(tf.constant(0, dtype=tf.float32, shape=[size])) def encode(self, X): return self.sess.run(self.h1_out, feed_dict={self.input: X}) def decode(self, h): return self.sess.run(self.out, feed_dict={self.h1_out: h}) def reconstruct(self, X): return self.sess.run(self.out, feed_dict={self.input: X})
2、加载数据和预处理
from keras.datasets import mnist (X_train, y_train), (X_test, y_test) = mnist.load_data() import randomX_train = X_train.reshape(-1, 784) # 测试集里随机10个图片用做测试 test_idxs = random.sample(range(X_test.shape[0]), 10) data_test = X_test[test_idxs].reshape(-1, 784) # 标准化 import sklearn.preprocessing as prep processer = prep.StandardScaler().fit(X_train) # 这里还是用全部数据好,这个也很关键! X_train = processer.transform(X_train) X_test = processer.transform(data_test) # 随机5000张图片用做训练 idxs = random.sample(range(X_train.shape[0]), 5000) data_train = X_train[idxs]
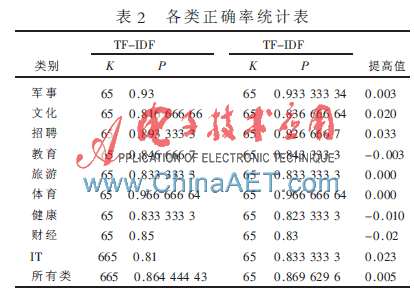
![图片[2]-TensorFlow自编码器(AutoEncoder)之MNIST实践-唐朝资源网](https://images.43s.cn/wp-content/uploads//2022/06/1655191218734_3.jpg)
3、训练
model = AutoEncoder(784, 200, 0.001) # 学习率对loss影响也有点大 model.fit(data_train, batch_size=128, epoches=200) # 200轮即可
4、测试、视觉对比图
decoded_test = model.reconstruct(X_test) import matplotlib.pyplot as plt %matplotlib inline shape = (28, 28) fig, axes = plt.subplots(2,10, figsize=(10, 2), subplot_kw={ 'xticks': [], 'yticks': [] }, gridspec_kw=dict(hspace=0.1, wspace=0.1)) for i in range(10): axes[0][i].imshow(np.reshape(X_test[i], shape)) axes[1][i].imshow(np.reshape(decoded_test[i], shape)) plt.show()
结果如下:
以上,点高斯噪声可以添加到输入以增加鲁棒性。
© 版权声明
本站下载的源码均来自公开网络收集转发二次开发而来,
若侵犯了您的合法权益,请来信通知我们1413333033@qq.com,
我们会及时删除,给您带来的不便,我们深表歉意。
下载用户仅供学习交流,若使用商业用途,请购买正版授权,否则产生的一切后果将由下载用户自行承担,访问及下载者下载默认同意本站声明的免责申明,请合理使用切勿商用。
THE END




















暂无评论内容