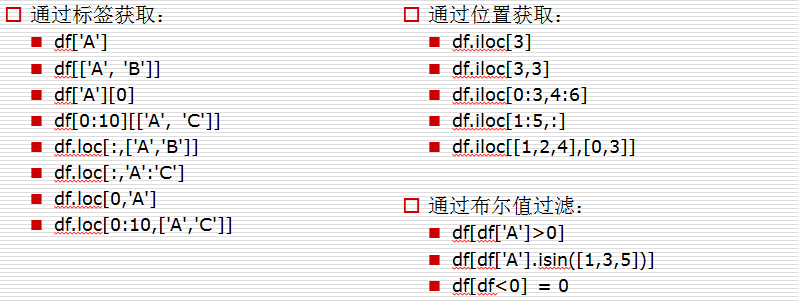



在写例子的时候,我使用了缺失值的填充,所以我想使用方法参数并传入'ffill'来实现。
但我发现这种填充方式并不完全是我想要的。

经过仔细的实验,我发现有一些需要注意的地方。
fill_test = Series([111, 222, 533, 644, 299], index=[1, 2, 3, 7, 11])
print(fill_test)
fill_test_1 = fill_test.reindex(index=[1, 2, 3, 7, 11, 4], method='ffill')
print(fill_test_1)
fill_test_1[4] = 555
print(fill_test_1)
fill_test_2 = fill_test_1.sort_index().reindex(index=[1, 2, 3, 8], method='ffill')
print(fill_test_2)
fill_test_3 = fill_test_1.sort_index().reindex(index=[1, 2, 3, 8], method='nearest')
print(fill_test_3)
fill_test_4 = fill_test_1.sort_index().reindex(index=[1, 2, 3, 9], method='nearest')
print(fill_test_4)

如上所述,您需要确保原始数据的索引是单调递增的。 (该值不影响)
当您在第二步中添加 4 时,您更改了此属性。
所以如果要修改索引,就需要一个sort_index()。
如果重新索引时,填写的索引不是单调递增的,还需要使用sort_index()来保证排序。
另外pandas去掉缺失数据,补充的值是基于你原始数据集中的前向填充,即第四步中8对应的值是原始数据中7对应的填充pandas去掉缺失数据,而不是复制的数据对应的数据3.
第五步,最近法实现最接近填充。 原始数据中,有索引7和索引11的数据,此时索引8和9的值被填充,可以看到前一个。 显然,后者使用的是索引为11的数据。
多于。
参考:
© 版权声明
本站下载的源码均来自公开网络收集转发二次开发而来,
若侵犯了您的合法权益,请来信通知我们1413333033@qq.com,
我们会及时删除,给您带来的不便,我们深表歉意。
下载用户仅供学习交流,若使用商业用途,请购买正版授权,否则产生的一切后果将由下载用户自行承担,访问及下载者下载默认同意本站声明的免责申明,请合理使用切勿商用。
THE END















暂无评论内容