


It brings me back to the fact that a word appears once even if it actually appears more than once.
如果不同,发布的代码将获得字数统计,例如相同的单词但计数不同(例如 1 和 2)。
我认为你的意思是同一个单词出现在矩阵的多行上,然后该行的每次出现都计为 +1。
如果我运行这个例子:
matrix =[['a', 'b', 'b', 'a'],
['a', 'b', 'b', 'a', 'a', 'b', 'b', 'a'],
['e', 'f', 'g'],
['e', 'f', 'e', 'a', 'b', 'b', 'a', 'a', 'b', 'b', 'a', 'h']]
words = ['abba']
result = right(words, matrix)
result
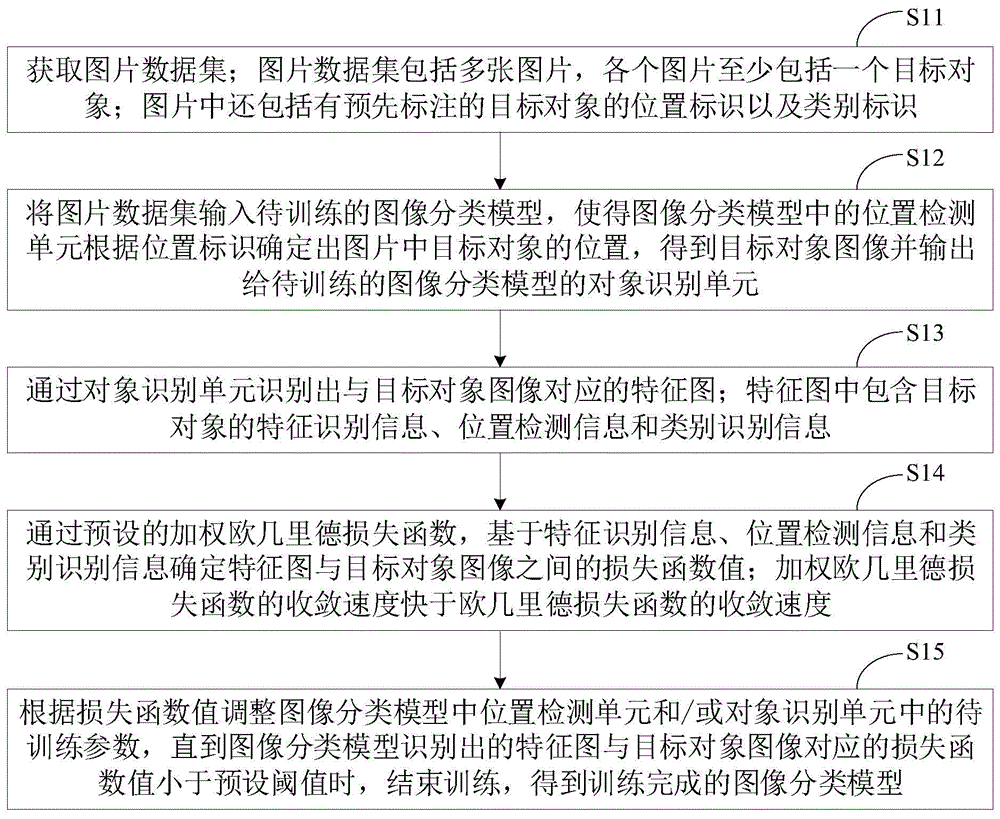
使用我看到的帖子中给出的代码
>>> result
[('abba', 1), ('abba', 2)]
而你想要的是:[(‘abba’, 2)].
在这里,我将保留一个单词字典以及它们在一行中出现的频率,并在最后转换为元组列表,假设您希望问题中的结果采用该格式。
def right(words, matrix):
word_occur = dict()
one_word = [''.join(row) for row in matrix]
for word in words:
if word in one_word:
word_occur[word] = word_occur.get(word,0) + 1
return [item for item in word_occur.items()]
在我给出的例子中
[('abba', 3)]
评估第 1、2 和 4 行。对于它给出的评论中提供的示例:
[('app', 2), ('nner', 1)]
这听起来像你想要的。
© 版权声明
本站下载的源码均来自公开网络收集转发二次开发而来,
若侵犯了您的合法权益,请来信通知我们1413333033@qq.com,
我们会及时删除,给您带来的不便,我们深表歉意。
下载用户仅供学习交流,若使用商业用途,请购买正版授权,否则产生的一切后果将由下载用户自行承担,访问及下载者下载默认同意本站声明的免责申明,请合理使用切勿商用。
THE END


















暂无评论内容